Metadaten im DataWarehouse
- Details
- Erstellt: 27. Oktober 2008
Einführung
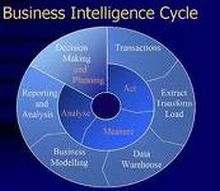
für den effizienten Betrieb eines DataWarehouse ist das Vorhandensein qualitativ hochwertiger Metadaten eine grundlegende Voraussetzung, da man sie zur Steuerung fast aller Prozessen eines DataWarehouse benötigt. Metadaten werden nicht nur für den Datenbeschaffungsprozess (Extraktion, Transformation, Laden), sondern auch für das eigentlich DataWarehouse-System (Analyse, Datenzugriff, Dokumentation, Benutzerführung) verwendet.
Zur Einordnung des Themas erfolgt zuerst eine kurze Vorstellung der Modellierungsebenen. Die folgenden Abschnitte enthalten neben einer allgemeinen Einführung in Metadaten und MetadatenManagement eine Klassifikation von Metadaten und die Vorstellung der wichtigsten Standards aus diesem Bereich.
Modellierungsebenen
Zur Modellierung eines komplexen Informationssystems sind im Allgemeinen vier Abstraktionsstufen notwendig (siehe Abbildung 1), wobei untergeordnete Ebenen durch die jeweils darüber liegende definiert werden.
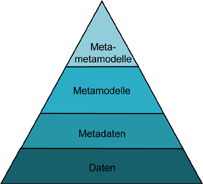
Daten
In dieser Ebene sind die konkreten Daten enthalten.
Metadaten
Diese Ebene beinhaltet die Metadaten zu den in der Datenebene beschriebenen Daten (z.B. Datenbankschema). Der Begriff der Metadaten wird nachfolgend näher erläutert.
Metamodelle
In einem Metamodell werden die Ausdrucksmöglichkeiten der Metadatenebene beschrieben. In einem späteren Abschnitt werden zwei konkrete Metamodelle im DataWarehouse-Bereich vorgestellt.
Metametamodell fasst die Metamodelle der dritten Ebene zusammen.
Abbildung 1: Modellierungsebenen
Im Folgenden liegt der Fokus der Betrachtung auf der Metadaten- und der Metamodellebene.
Metadaten Definition
Unter dem Begriff Metadaten versteht man gemeinhin jede Art von Information, die für den Entwurf, die Konstruktion und die Benutzung eines Informationssystems benötigt wird.
Die Metadaten eines DataWarehouse werden in einem Metadaten-Repository gespeichert und verfügbar gehalten.
Ein einfaches Beispiel für Metadaten sind Informationen über die Herkunft und den Zeitpunkt der letzten Änderung von Daten des DataWarehouse.
Aufgrund der Verwendung im DataWarehouse unterscheidet man drei verschiedene Arten der Nutzung von Metadaten:
Verwendet man Metadaten zur reinen Dokumentation, spricht man von einer passiven Nutzung.
Bei der Beschreibung von Prozessen (z.B. Transformationsregeln) mit Hilfe von Metadaten werden diese aktiv genutzt.
Die dritte Form der Verwendung von Metadaten ist eine semiaktive Nutzung, bei der die Metadaten nicht direkt zur Ausführung eines Prozesses benutzt werden (z.B. Schemainformationen).
Warum erfasst man Metadaten?
Die Erfassung der Metadaten im DataWarehouse dient im wesentlichen zwei Zielen:
zum einen soll mittels Metadaten der Aufwand für den Aufbau und den laufenden Betrieb des DataWarehouse- Systems minimiert werden, zum anderen soll durch Metadaten ein optimale Auswertung der Daten ermöglicht werden.
Zur Verwirklichung des ersten Zieles werden überwiegend die sogenannten technischen Metadaten eingesetzt, während man zur Gewinnung von Informationen eher Business-Metadaten benutzt.
Anforderungen an Metadaten-Repositorys
Um eine optimale Erfassung, Speicherung, Verwaltung und Benutzung von Metadaten zu gewährleisten, müssen Metadaten-Repositorys bestimmte Voraussetzungen erfüllen. Die Anforderungen an Metadaten und Metadaten-Repositorys sind den Anforderungen, die man an die Haltung ”normaler“ Daten und Datenbanken stellt, sehr ähnlich. Einige Punkte sind jedoch besonders hervorzuheben: Es muss ein umfangreiches, erweiterbares Metadaten-Metamodell geben, welches alle vorhandenen Klassen von Metadaten unterstützt. Dieses Metamodell soll auch dem Austausch und der Integration von
Metadaten dienen. Beispiele für Metadatenmodelle werden in einem späteren Abschnitt vorgestellt.
Für den Zugriff auf Metadaten müssen flexible Mechanismen existieren, die dem Kenntnisstand des Anwenders angepasst sind. Dies beinhaltet zum Beispiel die Möglichkeit einer Navigation entlang bestehender Metadatenbeziehungen.
Klassifikation von Metadaten
Man kann Metadaten nach verschiedenen Gesichtspunkten klassifizieren. Hier werden die Klassifikationen nach der Verwendung im DataWarehouse-Prozess, nach der Anwendersicht und nach der Datensicht vorgestellt.
Klassifikation nach der Anwendersicht
technische Metadaten
In dieser Klasse werden alle Metadaten, die für die technischen Benutzer eines DataWarehouse (Administratoren, Applikationsentwickler, aber auch ETL-Tools) wichtig sind, subsumiert. Dazu zählen zum Beispiel Zugangsrechte, Transformationsregeln und Datenbankkataloge.
Business-Metadaten
Das Ziel der Business-Metadaten ist es, den Benutzer mit allen Informationen zu versorgen, die er benötigt, um die Daten verstehen, finden und nutzen zu können. Dazu zählen zum Beispiel die Definition einer einheitlichen Terminologie und Informationen über vordefinierte Anfragen. Ein weiteres Beispiel für Business-Metadaten sind Aussagen über die Datenqualität. Unter diesem Begriff fasst man Angaben über die Herkunft, die Korrektheit und die Aktualität der Daten zusammen. Im Gegensatz zu technischen Metadaten spielt die Präsentation bei den Business-Metadaten eine wesentlich größere Rolle.
Klassifikation nach der Verwendung im DataWarehouse-Prozess
Populationsmetadaten
dazu zählen Informationen, die für den ETL-Prozess (Extract, Transform, Load) benötigt werden. Dies können zum Beispiel Informationen über den Datenursprung und die verwendeten Algorithmen, aber auch Protokolldateien und Ausführungspläne der Prozesse sein.
Designmetadaten
sind Daten, die das Schema des DataWarehouse und die Struktur der Daten betreffen.
Administrationsmetadaten
dokumentieren alle Administrationsinformationen, wie Zugriffrechte, physische Speicherungsorte und verwendete Protokolle.
Analysemetadaten
beschreiben zum Beispiel materialisierte Sichten, die für die Analyse verwendet werden (z.B. Aggregationstabellen), aber auch Informationen, die für die effiziente Auswertung von Anfragen nötig sind (z.B. statistische Informationen, Ausführungspläne).
Klassifikation nach der Datensicht
Die Klassifikation der Metadaten nach der Datensicht ergibt eine Unterteilung in Operationale Metadaten, DataWarehouse-Metadaten und DataMart-Metadaten. Zu der Klasse der Operationalen Metadaten gehören Informationen die für den Betrieb des DataWarehouse von Bedeutung sind (z.B. Transformationsregeln, Speicherplatzinformationen, Zugriffsrechte).
DataWarehouse-Metadaten betreffen das ganze Warehouse, wohingegen sich DataMart-Metadaten nur auf einen bestimmten DataMart beziehen.
Abbildung 2 zeigt die Zusammenhänge zwischen den vorgestellten Klassifikationskriterien. Eine wichtige Konklusion ist beispielsweise, dass die Administrationsmetadaten nicht für den Business User einsichtig sind.
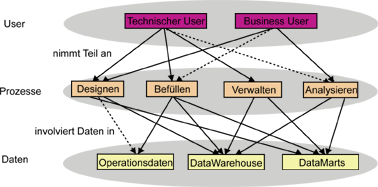
Abbildung 2: Klassifikation von Metadaten im DataWarehouse
Neben den erwähnten Klassifikationen sind auch noch Einteilungen der Metadaten nach dem Typ, der Abstraktion, der Herkunft und dem Erstellungs- bzw. Verwendungszeitpunkt gebräuchlich. Darauf wird hier aber nicht näher eingegangen.
Rolle von Metadaten im DataWarehouse-System
In diesem Abschnitt wird die Referenzarchitektur von DataWarehouse-Systemen beschrieben. Eine solche stellt idealtypisch die Architektur von DataWarehouse-Systemen dar. Die technische Umsetzung des DataWarehouse-Systems kann auf unterschiedliche Art und Weise erreicht werden, in Abhängigkeit der ausgewählten konkreten Software-Produkte für die einzelnen Komponenten.
Hier dient sie als Basis für die Erläuterung von Konzepten aus dem DataWarehouse-Bereich, da sie ein Modell- bzw. Vorgehensmuster für den zu modellierenden Sachverhalt darstellt. Besonders im Zusammenhang mit dem Metadatenkonzept ist ein fundamentales Verständnis über den Aufbau eines DataWarehouse notwendig, da Informationen über Daten (Metadaten) im gesamten Prozess des DataWarehousing eine entscheidende Rolle spielen.
Abbildung 3 zeigt schematisch den Aufbau einer Referenzarchitektur für ein DataWarehouse-System. Hierbei ist das Vorhandensein und der Zusammenhang der verschiedenen Operanden (Datenbehälter) wie Datenquelle und Arbeitsbereich, und Operatoren wie Extraktion und Laden ersichtlich. Hinzu kommt der Daten- und Kontrollfluss, der diese Komponenten miteinander verbindet. Besonders der Kontrollfluss spielt im Zusammenhang mit Metadaten eine entscheidende Rolle, da über diesen die einzelnen Komponenten miteinander kommunizieren. Wichtig ist hierbei, dass es sich um zwei Arten von Datenflüssen handelt. Zum einen um einen ordinären Datenfluss von der Quelle zur Analyse, zum anderen um einen Metadatenfluss zwischen Datenbehältern und dem Metadatenmanager.
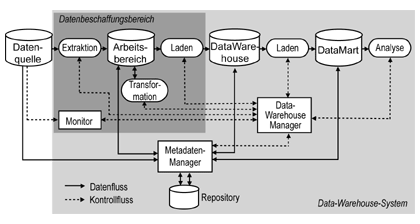
Abbildung 3: Referenzarchitektur
Datenquellen
Die für den DataWarehouse-Prozess notwendigen Datenquellen stellen den Ausgangspunkt dar. Dabei handelt es sich um mehrere zu integrierende, meist heterogene, reale Datenquellen (OLTP-Systeme, flat files, ect.). Aus ihnen werden mittels Extraktion Daten in einen Arbeitsbereich kopiert und dort anschließend transformiert. Besonders die Metadaten der Datenquellen sind für uns von Interesse. In einem früheren Abschnitt wurde bereits eine mögliche Klassifikation von Metadaten hinsichtlich der Nutzersicht in technische und Business-Metadaten vorgenommen. Im Zusammenhang mit den Datenquellen werden wir hierbei mit technischen Metadaten konfrontiert (z.B. mit Datenbankschema). Aus der Sicht des DataWarehouse-Prozesses handelt es sich hierbei um Populationsmetadaten.
Datenbeschaffungsbereich
Der Datenbeschaffungsbereich wird durch die Komponenten Extraktion, Arbeitsbereich, Laden, Transformation und Monitor gebildet. Dabei handelt es sich um Komponenten, deren primäre Funktion in der Datenbeschaffung liegt. Die Ergebnisse des Datenbeschaffungsbereichs stellen die Grundlage für das eigentliche DataWarehouse-System dar.
Arbeitsbereich
Der Arbeitsbereich, als Bestandteil der Datenbeschaffung, stellt wiederum seine Ergebnisse der Transformation der Daten in integrierter Form dem DataWarehouse zur Verfügung. In diesem Zusammenhang sei darauf hingewiesen, dass der Arbeitsbereich nicht notwendigerweise persistent sein muss, da die Ergebnisse der Transformation direkt in die DataWarehouse-Datenbank geschrieben werden können.
Monitor
Die Komponente Monitor unterstützt den Vorgang im Arbeitsbereich durch die Auswahl aller relevanter Daten aus den jeweiligen Datenquellen. Durch ihre Auswahlfunktion bestimmt sie daher maßgeblich die Qualität eines DataWarehouse-Systems.
DataWarehouse-System
DataWarehouse
Die Ergebnisse aus dem Datenbeschaffungsprozess dienen als Grundlage für das DataWarehouse. Dies ist durch eine Daten- und Schemaintegration unterschiedlicher Quellen gekennzeichnet. Somit stellt sie eine Basis für den späteren Analyseprozess dar. Dadurch, dass das DataWarehouse eine separate physische Ablage der Daten darstellt, können aufwendige Direktzugriffe auf die Datenquellen vermieden werden. Dies führt letztendlich zu einer einfacheren Datenintegration. Zusammen mit den dem DataWarehouse nachgeschalteten DataMarts ähnelt das DataWarehouse dem Ansatz von replizierten, förderierten Datenbanken. Im Unterschied zu jenen, weisen DataWarehouse-Systeme zusätzlich jedoch einen Auswertungsaspekt in Form einer Analysekomponente auf.
DataWarehouse-Manager
Als eine weitere Komponente ist der DataWarehouse-Manager zu nennen. Dieser stellt die zentrale Komponente eines DW-Systems dar. Dabei ist er für die Initiierung, Steuerung und Überwachung der einzelnen Prozesse (Extraktion, Transformation, Laden und Analyse) verantwortlich. Weiterhin dient er der zentralen Steuerung der DataWarehouse-Komponenten - Monitor, Extraktion, Transformation, Ladekomponente und Analysekomponente.
DataMart
Bei der Komponente DataMart handelt es sich um die zu Grunde liegende Datenbank, die für Analysezwecke aufgebaut wird. Zusammen mit Repository und dem DataWarehouse enthält das DataMart alle für die Analyse notwendigen Daten. Im Gegensatz zur anwendungsneutralen Darstellung der Daten im DataWarehouse orientiert sich hier die Strukturierung der Daten an den Analysebedürfnissen des Anwenders. Dabei werden die bereits bereinigten und integrierten Daten aus dem DataWarehouse bezogen. Dagegen werden die anfallenden Metadaten (DB-Schema) über den Metadatenmanager mit dem Repository abgeglichen. So können die für die DataWarehouse-Komponente relevanten Nutzerpräferenzen (z.B. häufige Anfragen an das DataWarehouse-System) in Form von Metadaten abgelegt werden.
Analysekomponente
Die Analysekomponente ist für den Kernzweck des DataWarehousing (Prozess des DataWarehouse) verantwortlich. Hier werden alle Operationen, die Daten aus dem DataWarehouse beziehen, durchgeführt. Die Analyse beinhaltet dabei die Anfrage und Visualisierung, sowie die Anwendung von Analysefunktionen auf Daten zur Generierung neuer Informationen (Data-Mining). Die Ergebnisse von Analysen werden anschließend wieder zurück in die Basisdatenbank bzw. das DataWarehouse geschrieben, um für spätere Analysen zur Verfügung zu stehen. Weiterhin wird in dieser Komponente die Präsentation der Daten und Analyseergebnisse vorgenommen. Wichtig dabei ist, dass die Darstellungsform (Data Access, OLAP, Data-Mining) maßgeblich von der Qualität der verwendeten Metadaten abhängt. Sollen komplexe Verfahren wie das Data-Mining durchgeführt werden, so müssen dies die vorliegenden Metadaten zulassen.
Repository
Im Repository werden schließlich alle Metadaten des DataWarehouse abgelegt. Bei Metadaten handelt es sich um Informationen, die den Aufbau, Wartung und die Administration eines DataWarehouse-Systems entscheidend erleichtern und die Informationsgewinnung aus dem DataWarehouse ermöglichen. Metadaten umfassen daher sowohl beschreibende (Informationen über Daten) als auch prozessbezogene (Informationen über die Verarbeitung der Daten) Daten. Die Metadaten des Repositorys sind schließlich sowohl Informationslieferant für Anwender und Administrator als auch Steuerungselement des DataWarehouse-Managers für die verschiedenen Prozesse im DataWarehouse.
Metadatenmanager
Den letzten Bestandteil des DataWarehouse-Systems stellt der Metadatenmanager dar. Dieser steuert die Metadatenverwaltung des DataWarehouse-Systems. Hierbei handelt es sich um eine DB-Anwendung mit Konfigurationsmanagement, Zugriffs-, Anfrage- und Navigationsmöglichkeiten für Metadaten. Damit die Komponenten des DataWarehouse Metadaten verwenden und auch aktualisieren können, bietet der Metadatenmanager ein Application Programming Interface (API) für den Zugriff auf das Repository an. Letztendlich ergibt sich der Kontrollfluss zwischen dem DataWarehouse Manager und dem Metadatenmanager aus den metadatengesteuerten Prozessen. Hierbei werden die Metadaten über den Metadatenmanager aus dem Repository geholt und an den DataWarehouse Manager zur weiteren Verarbeitung übergeben. Dieser liefert im Idealfall diese Metadaten an metadatenfähige Werkzeuge, die diese interpretieren und ausführen.
Der Metadatenmanager verarbeitet technische Metadaten für die Komponenten Datenquelle und Arbeitsbereich. Business-Metadaten werden hingegen mit Komponenten wie DataWarehouse, DataMart und Analyse ausgetauscht.
Metadaten bürgen für die Qualität
Vorstehend wurde der idealtypische Aufbau eines DataWarehouse-Systems mit seinen Komponenten und Zusammenhängen ausführlich beschrieben. Auffällig hierbei war, dass Metadaten sowohl für jede einzelne Komponente als auch für den gesamten DataWarehouse-Prozess eine entscheidende Rolle spielen. Die Qualität eines DataWarehouse-Projekts wird daher entscheidend von der Qualität der verwendeten Metadaten bestimmt. Somit kommt der Auswahl und der Pflege der Metadaten eine besondere Rolle zu.
Standards und Referenzmodelle
Dieses Kapitel widmet sich Standard- bzw. Referenzmodellen, um die in einem früheren Abschnitt vorgestellten Kriterien zur Klassifikation von Metadaten in einem Metadatenschema darzustellen. Im Bereich der DataWarehousing-Standards haben sich zwei Repräsentationsmodelle auf Basis der Unified Modeling Language (UML) zur Repräsentation der DataWarehouse-Metadaten und XML als Austauschformat etabliert:
-
Open Information Model (OIM) der Meta Data Coalition (MDC)
-
Common Warehouse Metamodel (CWM) der Object Management Group (OMG)
Im September 2000 ist die MDC ein Teil der OMG geworden, mit der Folge, dass das Open Information Model zugunsten des Common Warehouse Metamodel aufgegeben wurde. Im CWM sollen nun die überzeugendsten Konzepte beider Standards vereinigt werden und durch eine breite Herstellerunterstützung ein allgemein akzeptierter DataWarehouse-Metadaten-Standard geschaffen werden.
Da das OIM noch in Implementierungen verwendet wird, sollen seine grundlegenden Konzepte an dieser Stelle ebenfalls vorgestellt werden. Künftige Entwicklungen im DataWarehouse-Bereich werden sich aber am Common Warehouse Metamodel orientieren.
Open Information Model
Dieses Modell wurde von MDC mit dem Ziel entwickelt, die Interoperabilität zwischen Werkzeugen zu verbessern. Unter Interoperabilität versteht man einen einfachen Austausch von Daten zwischen verschiedenen Applikationen, in unserem Falle zwischen verschiedenen Werkzeugen. Durch die Definition eines gemeinsamen Modells für Informationen und Daten sollte der reibungslose Austausch von Informationen bzw. Daten zwischen Applikationen ermöglicht werden. Zu diesem Ziel schlossen sich viele Firmen zusammen, um den OIM 1.0- Standard zu definieren.
Es sollte ein domänenspezifisches Modell für das DataWarehousing eingeführt werden. Der 1.0 Standard von OIM umfasst dabei Submodelle wie Analyse- und Design-Modell, Objekt- und Komponentenmodell, Business-Engineering-Modell, Knowledge-Management-Modell sowie das für unseren Zweck interessante Datenbank- und DataWarehouse-Modell.
Das Modell für den Datenbank- und DataWarehouse-Bereich behandelt Metadaten mit Schwerpunkt auf den technischen Metadaten. Dabei wird eine Klassifizierung hinsichtlich ihrer Ausprägung gemacht. So beinhalten Elemente wie Datenbankschemata Informationen über relationale Datenbanken wie Tabellen, funktionale Abhängigkeiten, Schlüssel, etc.
OLAP-Schemaelemente beschreiben hingegen das multidimensionale Datenmodell mit den Elementen wie Würfel (z.B. Verkäufe), Dimension (z.B. Zeit) und Klassifikationshierarchie (z.B. Tag-Monat-Jahr). Weiterhin können Transformationselemente, die den Datenbeschaffungsprozess steuern, als auch satzorientierte Datenbankschemata identifiziert werden.
Common Warehouse Metamodel
Im Mittelpunkt der Entwicklung des Common Warehouse Metamodell (CWM) stand wie schon bei der OIM-Spezifikation die Interoperabilität von DataWarehouse-Metadaten im Hinblick auf einen einfachen Austausch zwischen Repositorys und Werkzeugen.
Erkennbar hierbei ist, dass der Fokus wieder auf technischen Metadaten liegt. Dabei wird ähnlich wie bei der OIM-Spezifikation eine Unterscheidung bezüglich des physischen Modells (Designmetadaten) der zugrundeliegenden Daten gemacht - relationales, satzorientiertes bzw. multidimensionales Modell. Zusätzlich wird jedoch eine Abgrenzung bezüglich des zugrundeliegenden Transformationsmodells (Populations- bzw. technische Metadaten) gemacht (z.B. OLAP-Modell).
Zusammenfassung
Dieser Aufsatz sollte einen Einblick in die Thematik “Metadaten und DataWarehouse“ geben. Besonders die vielseitige Verwendung von Metadaten im DataWarehouse-Kontext zur Beschreibung von Daten, Komponenten und Prozessen erfordert ein tiefes Verständnis. Ein jedes DataWarehouse-Projekt steht und fällt mit der Auswahl und der Qualität seiner Metadaten.
(Teilweise entnommen einem Themenpapier von Frank Legler und Anatolij Zubow, WS 2002/2003 an der Humboldt-Universität zu Berlin)